The goal of probabilistic modelling is to learn a model pθ(x) to fit the training dataset Xtrain={x1,⋯,xN}∼pd(x), where pd(x) is the unknown data distribution. A common training criterion is the maximum likelihood learning:
θmaxN1n=1∑Nlogpθ(xn).
The generalization of the pθ(x) can be evaluated using the test log-likelihood M1∑m=1Mlogpθ(xm′) with the test dataset Xtest={x1′,…,xM′}∼pd(x). This definition of generalization has an important practical implicaition: by using the mdoel pθ(x), we can design a compression algorithm to compress a data x′ losslessly into a binary string whose length is approximately −log2pθ(x′). Therefore, a better generalization, as measured by the test log-likelihood, translates to enhanced performance in practical lossless compression. A detailed discussion on the this connection can be found in David MacKay's textbook.
Furthermore, it's noteworthy that this perspective on lossless compression has been instrumental in recent efforts to understand the generalization properties of large language models, see the video by Ilya Sutskever for a discussion.
2. Introduction of VAE
Variational Auto-Encoder (VAE) is a latent variable model with the form
pθ(x)=∫pθ(x∣z)p(z)dz,
where the pθ(x∣z) is the deocder and p(z) is the prior. When pθ(x∣z) is parameterized by a neural network, the integration over z is is usually not tractable. A lower-bound of the log-likelihood can be used, which is refered to as the ELBO
where pθ(z∣xn) is the true posterior pθ(z∣xn)∝pθ(xn∣z)p(z). The VAE has been successfully used in lossless compression and the test compression length is approximately equal to the negative (log2) ELBO, see the BB-ANS paper for a practical guidence. Therefore, we will then focus on the generalization of the ELBO.
1. Generalization Gaps of VAE
This empirical ELBO objective can be further represented as a combination of a model empirical approximation and an amortized inference empirical approximation:
If either the decoder pθ(x∣z) or the encoder qϕ(z∣x) is overly flexible, it can cause the VAE to overfit to the training data. We can define the ELBO generalization gap (EGG) as the difference between the training and test ELBO
For simplicity, considering a flexible amortized inference network, we can assume that for any training data point xn∈Xtrain, the qϕN∗(z∣xm′) can generate the optimal posterior within the variational family Q:
However, when qϕ∗(z∣xn) overfits to Xtrain, qϕ∗(z∣xm′) may not be a good approximation to the true posterior pθN∗(z∣xm′) for test data xm′∈Xtest. This discrepancy can lead to a suboptimal test ELBO.
To illustrate the generalization of the amortized inference, we denote the ϕM∗ as the optimal realizable parameter of the amortized inference for the test data xm′∈Xtest:
Intuitively, AIGG assesses the proximity of the posterior qϕN∗(z∣xm′), — which is derived from the amortized network trained on Xtrain — to the optimal realizable posterior for xm′∈Xtest. Equivalently, the AIGG can also be written as the difference between two ELBOs with ϕM∗ and ϕN∗ respectively:
It is important to emphasize that this gap cannot be reduced by simply using a more flexible variational family Q. While this might reduce the KL(qϕN∗(z∣xn)∣∣pθN∗(z∣xn)) for the training data xn∈Xtrain, it would not explicitly encourage a smaller AIGG.
The AIGG is caused by the overfitting of the amortized inference (encoder). To understand the generalization property of the decoder, we can further rewrite the EGG by subtracting and adding the term M1∑m=1MELBO(xm′,θN∗,ϕM∗):
where the second term is just the AIGG. Meanwhile, we define the expression in the first term, which is the difference between the training and test ELBO using the optimal amortized inference parameters ϕN∗,ϕM∗ respectively, as the Generative Model Generalization Gap (GMGG), which can isolate the degree of which part affect the overall generalization.
GMGG=Training ELBO with optimal inferenceN1n=1∑NELBO(xn,θN∗,ϕN∗)−Test ELBO with optimal inferenceM1m=1∑MELBO(xm′,θN∗,ϕM∗)
With this in perspective, we can express the EGG as a combination of both gaps:
EGG=GMGG+AIGG,
This decomposition highlights that the VAE's generalization performance is influenced by the generalization capabilities of both the generative model and the amortized inference.
3. Visualization of the Generalizatio Gaps
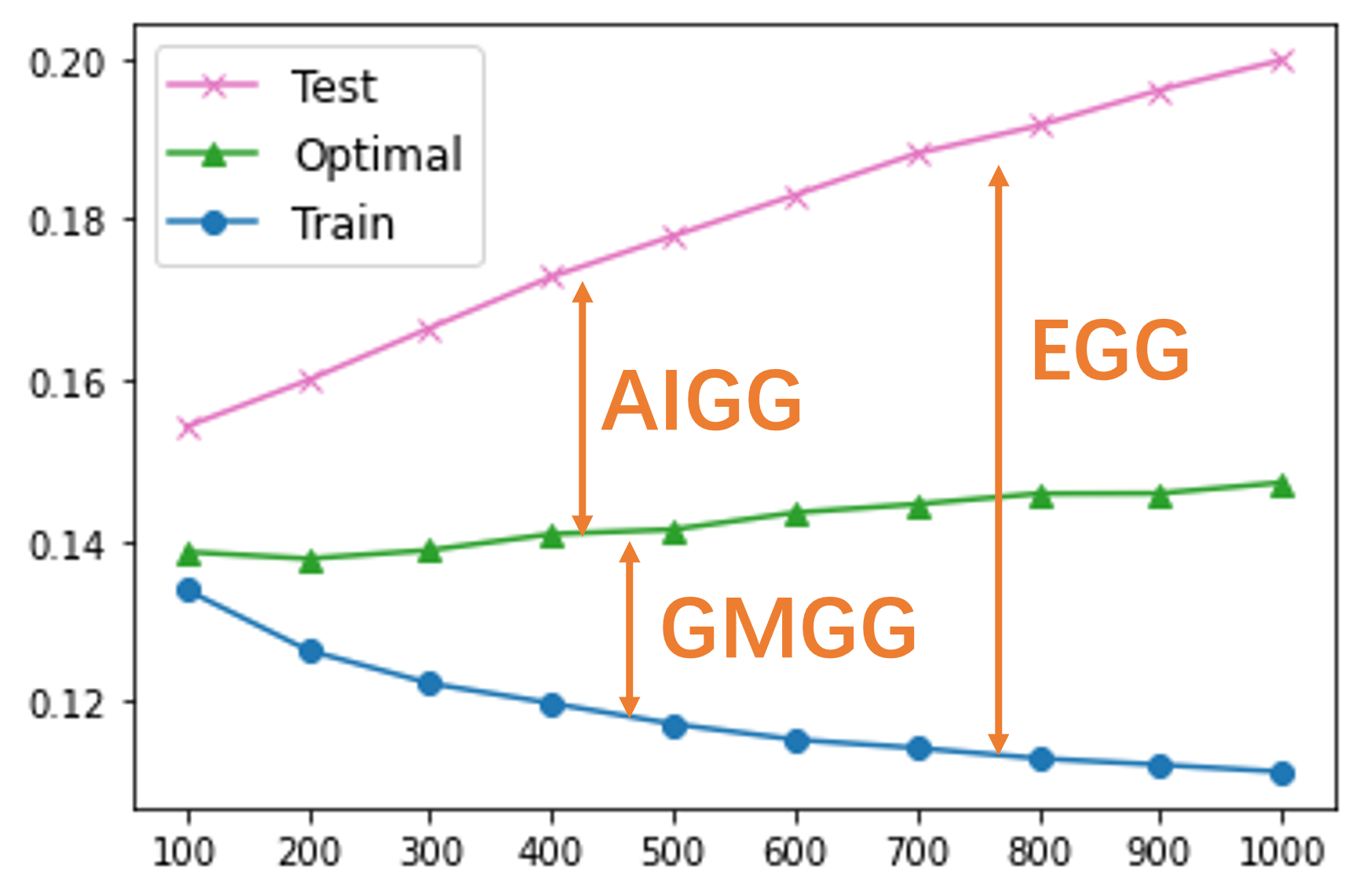
To visualize the generalization gaps, we trained a VAE on the Binary MNIST training dataset for 1,000 epochs. For every 100 epochs, we fix the decoder pθ(x∣z) and only train qϕ(z∣x) for 1k epochs on the test data to obtain the estimation of the optimal amortized posterior qϕM∗.
We can see the VAE overfits the training dataset easily. We also notice that utilizing the test ELBO with the test-time optimal inference strategy, the test BPD (green) appears largely stable, showing just a minor increase during training. This pattern hints at the overfitting of the generative model (decoder) being less pronounced compared to that of the amortized inference network (encoder). Consequently, the primary source of significant overfitting is dominated by the overfitting of the amortized inference network.
Using this observation, we can design algorithm to alleviate the overfitting of the amortized inference. Please see our NeurIPS paper Generalization Gaps in Amortized Inference for the furthur discussion how to reduce the generalization gaps of VAE.
I would to thank Prof. Yee Whye Teh for the constructive feedbacks on this topic during my PhD Viva.