- Published on
A Failure Case of VAE
The Variational Auto-Encoder (VAE) has been widely used to model complex data distributions. In this post, we discuss a simple but important failure mode of VAEs as well as a solution proposed in the paper Spread Divergences to fix the broken VAE. The code to reproduce the experiments behind the figures can be found here.
1. Introduction of VAE
Given a dataset sampled from some unknown data distribution , we are interested in using a model to approximate . A classic way to learn is to minimize the KL divergence:
From the definition of "divergence", we know that:
The integration over can be approximated by the Monte-Carlo method:
When , minimizing the KL divergence is equivalent to Maximum Likelihood Estimation (MLE). For a latent variable model with parameterized by a neural network, the log-likelihood is usually intractable. We can instead maximize the Evidence Lower Bound (ELBO):
Where is the amortized posterior that is introduced to approximate the true model posterior . The training objective becomes maximizing .
2. A failure case
Let’s consider the following data generation process for data :
We also plot the data samples:

We attempt to learn this distribution with a VAE of the following form:
- : 2D Gaussian with learned mean and variance;
- : 1D Bernoulli with mean equal to 0.5;
- : 1D Bernoulli with learned mean.
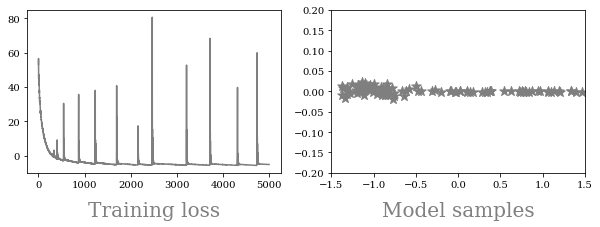
If we plot the training loss and samples from the resulting trained VAE we find that the training is unstable and the quality of the samples is bad.
2. Why the failure happens?
Computational: The y-axis of the has 0 variance, and so the variance of the y-axis in converges to 0 during training and the log likelihood becomes infinity.
Theoretical: The data distribution is a 1D manifold distribution that lies in a 2D space. Its density function is not well-defined (the distribution is not absolutely continuous w.r.t. Lebesgue measure.), so the KL divergence and MLE are ill-defined or cannot provide valid gradients for training. This problem has also been previously discussed in Wasserstein GAN.
3. A simple fix: spread KL divergence
A simple trick to fix the problem is adding the same amount of convolutional noise to both data distribution and model . For example, we can choose a Gaussian noise distribution and let:
We further define the spread KL divergence as:
Our paper shows that for some certain noise distributions (e.g. Gaussian), we have:
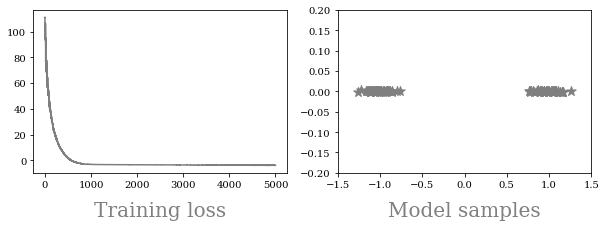
This provides a good estimation for and can provide valid gradients for training. When we train with spread KL divergence, the result becomes much better:
3. Conclusion
Even a simple model like VAE can fail in a seemingly straightforward situation due to both computational and theoretical reasons. Recognizing these pitfalls can help us design better models. A simple but effective fix is to spread the KL divergence, which provides valid training signals and fixes the problem.
This note was written in 2019, but I still found it interesting at the end of 2021, so I made it my first blog post. I want to thank Peter Hayes for useful feedbacks. Hope you enjoy it and happy new year!